
Künstliche Intelligenz und maschinelles Lernen sind neben den üblichen Buzzwords wie „Big Data“, „Industrie 4.0“ und „Block Chain“ in aller Munde. Jedoch ist es, ähnlich wie bei den anderen Begriffen, oft nicht einfach, die genaue Bedeutung dahinter zu entschlüsseln. Das macht es für Nicht-Experten häufig unmöglich abzuleiten, was „heiße Luft“ und was zukunftsweisende Technologie ist.
In diesem Whitepaper möchten wir uns intensiv mit den Begriffen der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML) beschäftigen, welche eng miteinander verwoben sind. Viele der uns bekannten Blogeinträge oder Whitepaper überfliegen diese Themen entweder sehr oberflächlich oder mit dem Ziel, ein bestimmtes Produkt für exakt einen Anwendungsfall zu verkaufen. Diese Lücke wollen wir mit diesem Whitepaper schließen. Selbstverständlich haben auch wir ein offenes Interesse daran, KI-Projekte durchzuführen – jedoch technologieunabhängig und gut informiert!
Somit haben wir uns als Ziel gesetzt, Ihnen einen guten Einblick in verschiedene Felder der KI zu bieten, Ihnen dadurch ein Abwägen zwischen Pro und Contra zu ermöglichen und Sie auf eine eventuell bevorstehende „KI Revolution“ vorzubereiten. Bei alledem wollen wir aber die Realität nicht aus den Augen verlieren. Das bedeutet konkret: Wir sehen uns neben den rohen Begriffen und ihren Bedeutungen auch Fallbeispiele aus der „echten Welt“ an, um davon abzuleiten welche Handlungen heute notwendig sind, um langfristig am Markt teilnehmen zu können. Lassen Sie uns also ohne weitere Umschweife in die spannende Welt der Künstlichen Intelligenz einsteigen!

Quelle: Pixabay
Was ist Künstliche Intelligenz (KI)?
Bevor wir in den industriellen Nutzen von Künstlicher Intelligenz einsteigen, möchten wir einige Grundbegriffe sortieren, die häufig durcheinander geworfen werden: Ziel ist es, Sie zu befähigen den aktuellen Trends rund um KI und Maschinellem Lernen zu folgen und dadurch Handlungen für Ihr Unternehmen abzuleiten. Konkret geht es vor allem um die Frage: „Wann sollte Software auf herkömmlichen Wege programmiert werden und wann kommt für mein Unternehmen eine KI-Lösung in Betracht?“.
Definition
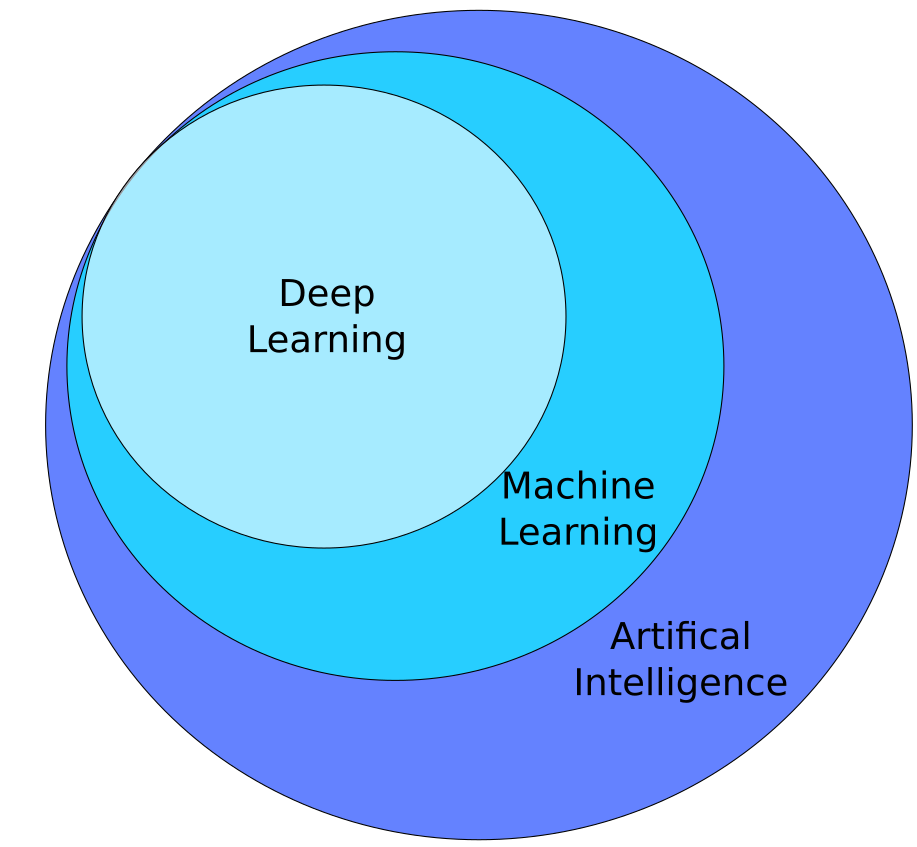
Wenn über KI bzw. auf Englisch: Artificial Intelligence (AI) diskutiert wird, werden häufig einige Begriffe verwendet, die wir hier zunächst in das richtige Licht rücken wollen. Künstliche Intelligenz, Maschinelles Lernen und Deep Learning werden nicht selten austauschbar verwendet, obwohl damit, technisch gesehen, unterschiedliche (Teil-)Bereiche der Künstlichen Intelligenz gemeint sind.
Widmen wir uns zunächst dem Oberbegriff des Themenfelds: Künstliche Intelligenz. Bei unserem ersten Begriff stoßen wir jedoch ebenfalls auf die erste Hürde: So richtig scharf ist KI leider nicht definiert. Jedoch taucht rund um diesem Begriff häufig die Definition von Marvin Minsky aus dem Jahre 1966 auf:
[…] [AI] is the science of making machines do things that would require intelligence if done by men.M. Minsky 1968 in Semantic Information Processing
Was frei übersetzt bedeutet:
[…] [KI] ist die Wissenschaft, welche sich damit beschäftigt Maschinen das tun zu lassen, was normalerweise menschliche Intelligenz benötigen würde.Übersetzung frei nach M. Minsky 1968 in Semantic Information Processing
Somit wird klar: Künstliche Intelligenz kann sehr Vieles sein! Von offensichtlichen Dingen, wie Smarthome-Assistants, die auf Zuruf die Wettervorhersage abrufen, bis hin zu Dingen, die man zunächst nicht mit KI in Verbindung gebracht hätte: Beispielsweise Navigationssysteme, die (im Gegensatz zur manuellen Routenplanung via Papierkarte) in Sekundenschnelle die kürzeste Route an einen beliebigen Zielort berechnen und dabei Streckenführung, Ampeln und den zur Reisezeit erwarteten Verkehr berücksichtigen. Bei dem Versuch der Abgrenzung von diesen KI-Anwendungen zu anderer „klassischer“ Software werden wir jedoch sehr schnell bemerken, dass das sehr schwer ist: Gehört eine Waschmaschine zu KI? Vermutlich nicht: Menschliche Intelligenz ist zum Drehen einer Trommel und dem gelegentlichen Zuführen von Wasser und Pulver nicht unbedingt notwendig. Trifft dasselbe aber auch für die Auswahl einer passenden Farbe für Text auf beliebigen Hintergründen zu? Vielleicht. Dabei sind wir am Kern angelangt: Es gibt keine scharfe Grenze zwischen einem ausreichend komplexen Algorithmus und einer KI. Rein die äußere Wahrnehmung diktiert hier, was eine KI genau ist.
Dabei ist es nur zu einfach dem sogenannten AI-Effect auf den Leim zu gehen, welcher besagt, dass Künstliche Intelligenz ab dem Zeitpunkt nicht mehr als KI wahrgenommen wird, ab dem ein Computer zum ersten Mal ein gegebenes Problem zuverlässig gelöst hat. Als Beispiel wird im verlinkten Artikel Schach aufgeführt: Ein (Schach-)Computer kann nach heutigen Standards mindestens genau so gut, wenn nicht besser als die besten Schachspieler der Welt Schach spielen. Jedoch würde heutzutage nicht jeder zustimmen, dass es sich dabei um Künstliche Intelligenz handelt: Es ist ja schließlich nur ein Programm mit „ein paar“ Regeln, die das Spiel nicht wirklich „versteht“. Ein Mensch, welcher ähnlich gut wie ein Schachcomputer spielt, würde jedoch als sehr intelligent angesehen werden, obwohl das Endergebnis, nämlich die Spielzüge, vergleichbar sind.
Um einen sehr komplexen Algorithmus, wie man ihn aus der bisherigen Informatik kennt, von einer KI zu unterscheiden, möchten wir Ihnen hier trotzdem ein paar nützliche Stichpunkte an die Hand geben. Dafür ist es dienlich, sich einige Eigenschaften von „offensichtlicher“ KI anzusehen und diese als Maßstab für die eigene Definition zu nehmen:
- Ein KI-Programm lernt durch bereitgestellte Daten oder hat die Möglichkeit von den produzierten Ergebnissen zu lernen
- Ein KI-Programm ist häufig, aber nicht immer, an Sensoren angeschlossen, um seine Umwelt wahrzunehmen und dynamisch auf diese zu reagieren
- Ein KI-Programm löst eine beliebig große (oder kleine) Domäne von Problemen eigenständig und zieht dabei Variablen in Betracht, welche gemeinsam betrachtet, eine sehr hohe Varianz aufweisen können (z.B. das Wetter kombiniert mit der Position von Mitarbeitern im Raum, kombiniert mit der Uhrzeit, um abzuleiten, wann ein Arbeitsraum am besten (automatisch) gesäubert werden sollte)
Da KI also ein sehr weites Feld und unzählige, teilweise noch zu entdeckende, Anwendungsgebiete umfasst, gibt es folglich entsprechend viele Unterbereiche, die sich auf die Lösung spezieller (Teil-)Probleme fokussieren.
Ein gängiger Begriff, der eine Untermenge von KI darstellt und welchem wir einen Großteil dieses Whitepapers widmen wollen, ist Maschinelles Lernen (engl. Machine Learning – ML). Maschinelles Lernen beschäftigt sich damit, wie man einem Computer „beibringen“ kann, eine bestimmte Aufgabe zu lösen, ohne ihm dabei den Lösungsweg z.B. durch „traditionelle“ Programmierung eines komplexen Algorithmus vorzugeben. Das Ziel von ML ist also die (automatisierte) Erstellung von Algorithmen, welche genutzt werden können, um hoch komplexe Probleme zu lösen, welche bisher nur durch menschliche Intelligenz gelöst werden konnten. Dabei ist eine einzelne KI-Anwendung meistens auf ein einzelnes stark eingegrenztes Problem spezialisiert und ist somit eine schwache KI. – Im Gegensatz zur futuristischen und universalen „Starken KI“, welche analog zum Menschen, mit Hilfe eines einzigen Programms beliebige Probleme lösen kann.
Die Lösung eines Problems durch eine durch ML trainierte KI kann verschieden motiviert sein: Entweder ist die Lösung für das vorhandene Problem unbekannt oder die Lösung ist so komplex, dass eine „klassische“ Programmierung viel zu lange dauern oder durch zeitliche Limitierungen nicht die benötigte Vielseitigkeit aufweisen würde. Ein hierfür häufig herangezogenes Beispiel ist die Bilderkennung: Um einen Hund auf einem Bild durch etablierte Techniken des Maschine Learning (z.B. das oft aufgegriffene Deep Learning) zu erkennen, benötigt es nur einen ausreichend schnellen Computer und ein paar Hundert bis ein paar Tausend Fotos von Hunden. Eine KI kann man mit diesen Bildern innerhalb von wenigen Stunden bis Tagen trainieren und wird zuverlässige Ergebnisse erhalten. Um das selbe Problem aber durch Programmierung zu lösen, wäre es notwendig eine Software zu schreiben, die alle möglichen Perspektiven eines Hundefotos mit den möglichen Rassen, Lichtbedingungen, Bildhintergründen, usw. berücksichtigt. Hieran kann man wahrscheinlich bereits jetzt herauslesen, dass dies eine Herkulesaufgabe für Monate oder länger wäre.
Somit erhalten wir durch Techniken des ML nun die Möglichkeit, Probleme zu lösen, welche bisher entweder gar nicht, nicht in vernünftiger Zeit oder nur sehr kostspielig lösbar gewesen wären. Jedoch hat neben ML auch die klassische Programmierung Ihre Daseinsberechtigung: Einige Probleme können wesentlich schneller programmatisch gelöst werden (wie z.B. das Entwickeln einer Kommunikationsschnittstelle Ihres Servers oder einer passenden UI) und andere Probleme können wesentlich schneller durch ML gelöst werden (wie z.B. das Erkennen von Produktionsfehlern bei einem Produkt oder der Voraussage des Umsatzes Ihres Sales-Teams im nächsten Quartal).
Unterschiede zwischen KI und Programmierung
Da es nun also zwei potentielle Lösungsansätze für ein Problem gibt, stellt sich folgerichtig die Frage: „Wann sollte ich welches Problem wie lösen?“ Beziehungsweise die Kernfrage: „Wann ist KI für mein Unternehmen sinnvoll?“
Da unser erklärtes Ziel in diesem Whitepaper ist, Ihnen das nötige Wissen zu vermitteln diese Frage für Ihr Unternehmen selbst zu beantworten, wollen wir hier eine möglichst präzise Unterscheidung der zwei Entwicklungsansätze anführen, da beide – technisch gesehen – ein von außen schwer unterscheidbares Stück Software produzieren.
Der klassische Ansatz: In der klassischen Software-Entwicklung werden Probleme in ihrer einfachsten Form durch „Wenn-Dann“-Konstrukte gelöst. Also: Wenn Situation A vorliegt, führe Aktion B aus oder komme zur Schlussfolgerung C. Dieser Ansatz funktioniert sehr gut für Ereignisse, die wir bereits erwarten und deren Bedingungen klar umrissen sind, z.B. der Form: Der Nutzer klickt auf einen Button, die App sendet eine Anfrage an einen Server, der alle Gegenstände der Lagerhalle zurück sendet, woraufhin die App die Gegenstände im Lager in einer Liste darstellt. Selbstverständlich können solche „Wenn-Dann“-Bedingungen verschachtelt werden und dadurch fast beliebig komplexe Probleme lösen, solange zur Zeit der Programmierung der Lösungsweg für diese Probleme klar vorgegeben ist.
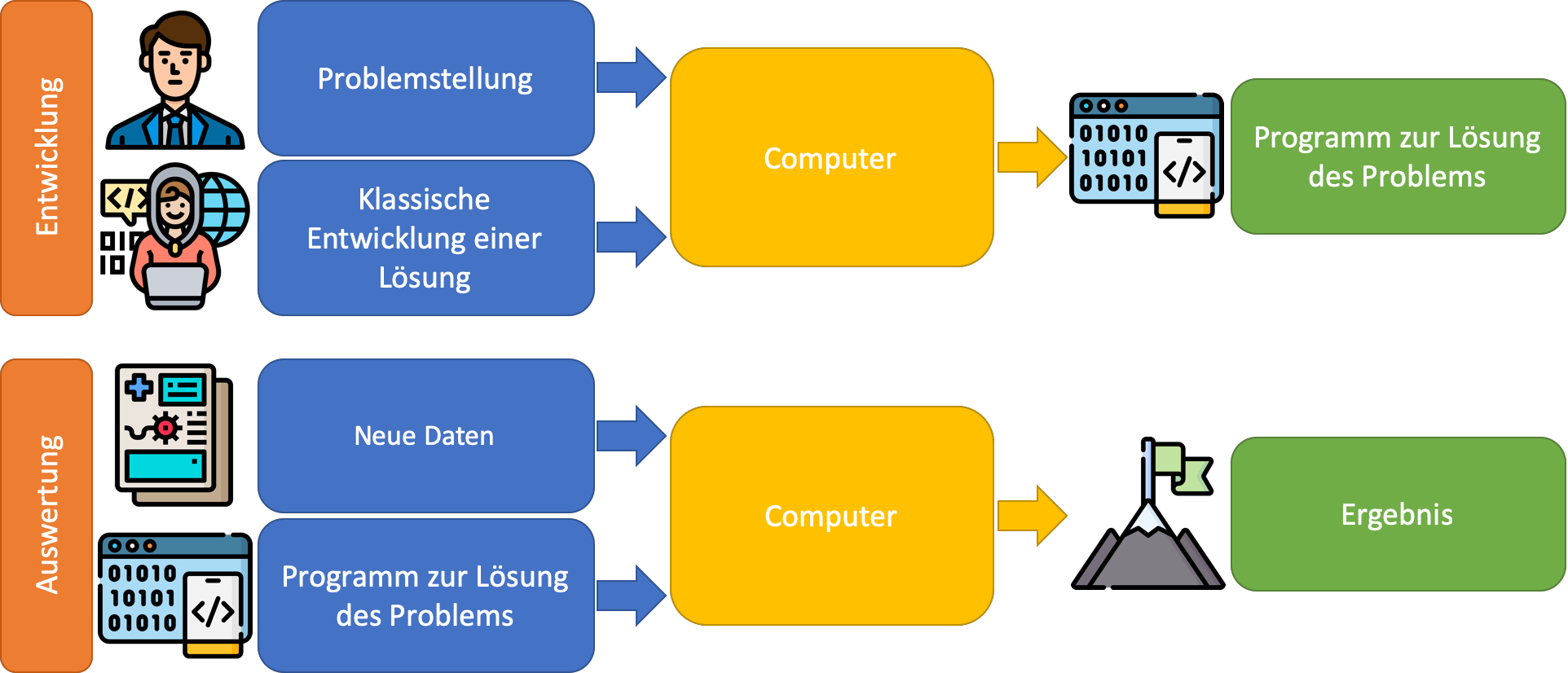
Quelle der Icons: Flaticon
Softwareentwicklung mit ML: In Kontrast dazu steht das maschinelle Lernen. Das Ergebnis dieses Prozesses ist ebenfalls ein Programm, das am Ende auch „nur“ ein Algorithmus ist, der aus Eingabewerten Ausgabewerte berechnet. Um eine Maschine nun dazu zu bewegen, etwas zu lernen, benötigt man, anders als in der bisherigen Softwareentwicklung, zunächst eine gute Datenbasis. Das liegt daran, dass das Maschinelle Lernen, ähnlich wie beim Menschen, auf „Erfahrung“ durch Beispiele setzt. Nun reicht es nicht, einem Computer einfach nur die Beispiele zu zeigen und zu beten, dass ein Wunder geschieht. Damit ein Computer versteht, was man von ihm will, verwendet man eine Mischung aus Informatik (das Vor- und Nachbereiten der Informationen) und Statistik (der „Erfahrung“).
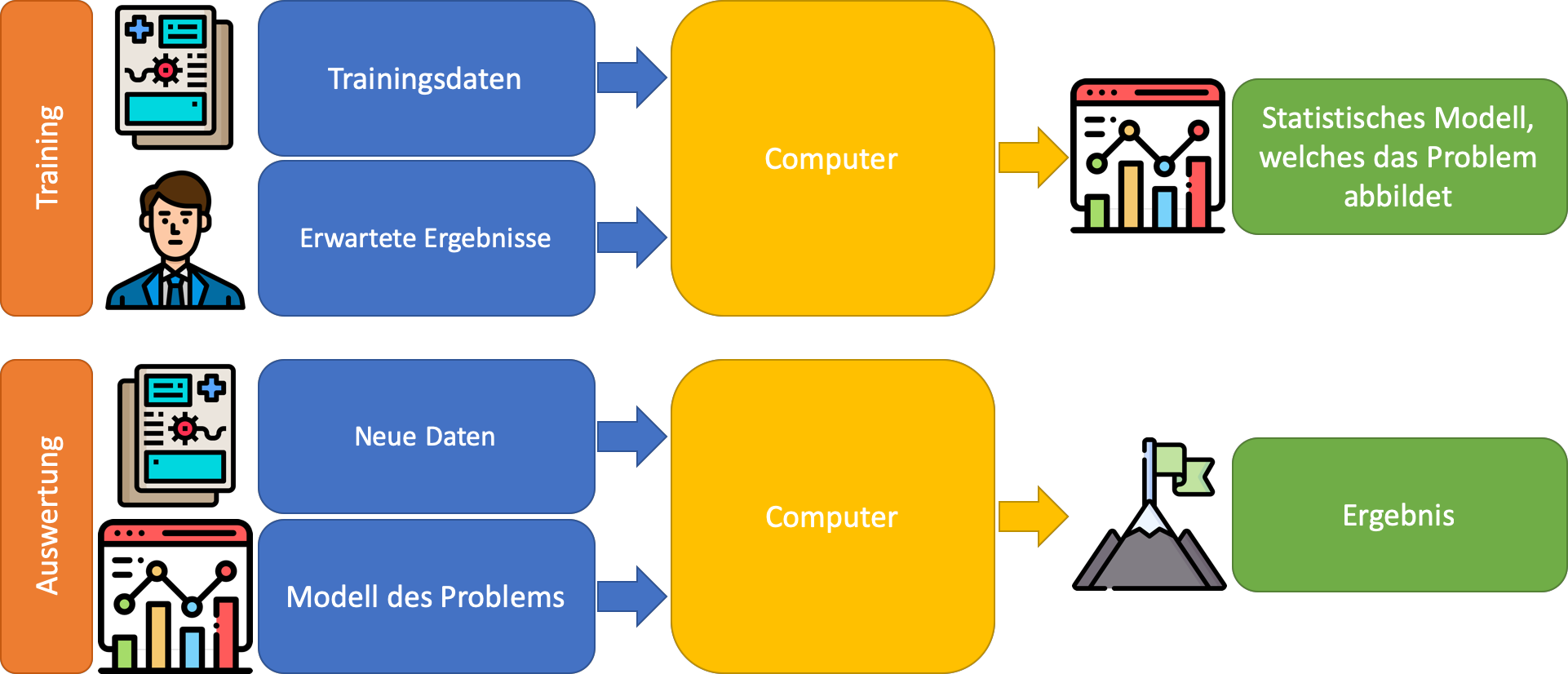
Quelle der Icons: Flaticon
Ziel des sogenannten Trainings einer KI ist, ein statistisches Modell zu erstellen, welches die ihm gezeigten Daten (Videos, Bilder, Tabellen, etc.) verwendet, um zwischen allen Daten einen statistischen Zusammenhang zu erkennen. Das Training selbst ist hierbei der uninteressanteste Schritt: Ein Algorithmus geht die Daten von A bis Z durch und passt dabei einige Variablen im zuvor vom Entwickler gewählten statistischen Modell an. Die eigentliche Arbeit besteht in den Schritten davor und danach! Bevor eine KI durch ML trainiert werden kann, müssen zunächst Daten gesammelt werden, da sie der Schlüssel zu einer erfolgreich trainierten KI sind. Hier gilt salopp: „Garbage in – Garbage out“. Wenn die gesammelten Datenpunkte nicht die Informationen enthalten, die benötigt werden, um das gewählte Problem zu lösen, dann wird ein Computer damit nicht mehr als ein Mensch anfangen können. Somit sollten die Trainingsdaten alle Informationen enthalten, die auch ein Experte benötigen würde, um eine fundamentierte Entscheidung zu treffen. Damit diese Daten nun von einem Computer richtig interpretiert werden können, benötigt es einen Daten- bzw. Statistik-Experten. Dieser Experte analysiert und konvertiert die Daten in einem sogenannten Preprocessing-Schritt so, dass er folgende Ziele erreicht:
- Die Daten sind nun maschinenlesbar, kompakter und ggf. schneller zu verarbeiten (Encoding)
- Nicht aussagekräftige Daten werden ganz oder teilweise entfernt (Cleaning)
- Fehlerhafte Daten, Ausreißer, Lücken und ähnliche Artefakte werden identifiziert und entsprechend korrigiert (Imputing)
- Weitere Daten werden aus vorhandenen Daten generiert (Data-Mining)
- Komplexe Zusammenhänge zwischen Datenpunkten und der gewünschten Lösung werden herausgearbeitet (Data-Exploration und -Enrichment)
Um diese Schritte auszuführen, ist es notwendig, dass der Daten-Experte ein möglichst vollumfängliches Verständnis für Ihre Daten hat. Idealerweise ist er ebenfalls Experte für das Anwendungsgebiet, kennt durch die Bedeutung der Werte genau und weiß auch welche Wertekombinationen üblich sind, welche Ausreißer darstellen oder welche wohl durch falsche Messung oder Fehlbedienung entstanden sind. Da dies nicht immer möglich ist, wird zur Analyse der Rohdaten meist ein explorativer Ansatz in Kooperation mit einem Domänenexperten gewählt: Die Daten werden genau mit einigen Standardinstrumenten untersucht, um Zusammenhänge aufzudecken. Diese werden danach iterativ mit dem Experten/Kunden diskutiert, um so auf der einen Seite ein gutes Verständnis für die Daten zu bekommen und auf der anderen Seite dem Kunden Einblicke in die gefundenen Zusammenhänge zu liefern. Dadurch ist es möglich mit Hilfe dieser Einblicke die Datenbasis weiter zu analysieren, bis schließlich jeder Tropfen Information der Datenmenge extrahiert ist.
Ab diesem Zeitpunkt ist dem Machine-Learning-Experten häufig bereits klar, welche statistischen Modelle sich für die gegebene Problemstellung eignen und welche nicht. Diese sogenannten Machine-Learning-Modelle werden mit Hilfe einer mathematischen Funktion (oder auch mehreren) aufgestellt, deren Variablen so optimiert werden müssen, dass sie möglichst gut alle Daten in der vorbereiteten Datenmenge beschreiben. Dieses Optimierungsproblem erfordert die eigentliche Rechenleistung: Verschiedene Variablenkombinationen werden strukturiert „durchprobiert“ und andere von den vorhandenen Daten abgeleitet, solange bis schließlich ein möglichst optimal trainiertes Modell herauskommt, welches das gegebene Problem für die zum Training verwendeten Daten löst. Wenn in diesem Schritt alles richtig gemacht wurde, kann das trainierte Modell auch das Problem für unbekannte/neue Datenpunkte lösen. Man sagt, dass das Modell generalisiert.
Schlussendlich obliegt es wiederum der „klassischen“ Programmierung das trainierte Modell zu integrieren und zu verwenden. Hierzu übergibt man dem Modell neue Daten im selben Format, welches auch die trainierten Daten hatten. Daraufhin werden die einzelnen Werte in die Formel eingesetzt und eine Lösung berechnet. Hierfür ist es häufig notwendig, den Preprocessing-Schritt zu automatisieren, damit neu eintreffende Daten in das selbe Format der Daten gebracht werden, welche auch für das Training verwendet wurden. Durch diese Automatisierung lassen sich „KI-Bausteine“ auch recht einfach in bereits existierende Software-Systeme integrieren, um „Intelligent Agents“ zu schaffen, welche ihre Umgebung, aus welcher die Trainingsdaten stammen, durch das Modell interpretieren und von den Ergebnissen entsprechende Handlungen ableiten.
Quelle: Pixabay
Wie kann KI meinem Unternehmen helfen?
Durch das vorangegangene Kapitel sollten Sie nun eine gute Idee von den Unterschieden zwischen trainierter KI und programmiertem Algorithmus bekommen haben. Klassischerweise wird Ihnen in diesem Kapitel von verschiedenen Stellen empfohlen, Standard-KI-Lösungen zu verwenden (z.B. Chatbots), welche „von der Stange“ bereit für den Einsatz sind. Diese eher kleinen KI-Lösungen können selbstverständlich auch Ihr Unternehmen unterstützen, jedoch ist es fraglich, ob diese Ihnen einen tatsächlichen Wettbewerbsvorteil bringen, da Ihre Konkurrenz vermutlich dieselben Tools bereits einsetzt. In diesem Artikel gehen wir darauf ein, wie Sie den Grundstein für ein Individual-KI-Projekt legen, damit Ihr Unternehmen in Zukunft als Game-Changer auf dem Markt auftreten kann.
Digitalisierung als Voraussetzung für KI-Lösungen
Wie zuvor erwähnt ist das A und O einer KI die Datenbasis. Ohne ausreichend Daten in passender Qualität kann auch der beste Machine-Learning-Experte nur kleine Erfolge erzielen. Was hierbei genau „ausreichend“ und „passend“ bedeutet, hängt von Fall zu Fall ab. Eine gute Regel ist: Je größer die Varianz der Daten ist, welche die gleiche Lösung generieren oder je ähnlicher sich Daten sind, die unterschiedliche Lösungen produzieren oder je mehr Variablen es in den Daten generell gibt, desto mehr Daten müssen gesammelt werden, um eine zuverlässige KI zu entwickeln. Bleiben wir also bei dem Beispiel von Hundebildern: Da sehr viele verschiedene Bilder mit Hunden die gleiche Ausgabe (nämlich „Hund“) liefern, dabei die Eingabedaten sehr gleich aussehen können (Bild 1: Eine Wiese; Bild 2: Eine Wiese mit Hund in der Ferne) und die Eingabedaten eine sehr hohe Dimension haben (nämlich einen (schwarz/weiß) bis drei (rot/grün/blau) Datenpunkte pro Pixel), benötigt man sehr viele Bilder, um dem Modell „klar zu machen“, worauf es in den Bildern wirklich ankommt.
Der gegenteilige Fall tritt ein, wenn ein Problem sehr klar umrissen ist und bestimmte Werte so gut wie immer zu einem eindeutigen Ergebnis führen. Dann kann man eine KI auch recht einfach mit Hilfe von wenigen, aber repräsentativen Datenpunkten trainieren. Ein simples Beispiel hierfür ist das Erkennen von Anomalien während des Betriebs einer Maschine. Anstatt alle möglichen Anomalien zu erkennen wird hier versucht der „Normalzustand“ einer Maschine zu erkennen. Der Grund hierfür ist einfach: Anomalien spannen ein großes Spektrum an möglichen Ausprägungen auf: Das macht es schwer ein Modell auf Basis von Abweichungen zu trainieren, da für ein zuverlässiges Modell viele Datenpunkte (mehrere pro möglicher Anomalie) benötigt werden würden. Es ist wesentlich einfacher das Modell anhand des Normzustands zu trainieren, da dieser ein wesentlich engeres Spektrum an möglichen Wertekombinationen aufspannt. Interessant wird Machine Learning hier, sobald das Modell ständig weiter „lernt“ (also wiederholt mit neuen Daten trainiert wird) und somit erkennt, dass der normale Wertebereich einer neuen Maschine anders aussieht, als der normale Wertebereich einer Maschine, welche bereits seit Jahren fast ununterbrochen läuft.
Damit Sie nun passende Daten in ausreichender Menge für Ihren Use-Case sammeln können, ist eine (teilweise) Digitalisierung existierender Prozesse eine zwingende Voraussetzung, was nebenbei bemerkt, auch zum Neudenken der Prozesse veranlassen sollte, da die Möglichkeiten der Digitalisierung über eine 1:1-Abbildung weit hinaus gehen! Daher ist es wichtig, bei der digitalen Transformation früh auf Experten zu setzen, die Ihnen helfen, digitale Konzepte zu erarbeiten und bereits früh die Anbindung an KI-Systeme einplanen, um vor deren Entwicklung die benötigte Datenbasis zu sammeln. Auch hier sind wir bei einer Kernaussage angelangt: Es ist nie zu früh mit dem Sammeln von passenden Daten zu beginnen! Wobei wir „passend“ betonen wollen, da eine willkürliche Datensammlungswut zum einen zu datenschutzrechtlichen Problemen führen könnte und zum anderen dem späteren KI-Experten Probleme macht „die Spreu vom Weizen“ zu trennen.
Beim Sammeln der Daten sollten Sie grundsätzlich zwischen zwei Kategorien unterscheiden: Strukturierte Daten und unstrukturierte Daten. Dabei können beide Arten sehr nützlich zur Lösungsfindung sein. Strukturierte Daten sind Daten, welche wir gewöhnlich in Datenbanken oder Excel-Listen finden und damit sehr leicht durchsuchen können. Unstrukturierte Daten hingegen, sind Daten, die „versteckte“ Informationen beinhalten, welche erst ausgearbeitet werden müssen, wie z.B. Fotos, Videos, Audiodateien oder Prosa. Unter anderem kann KI auch benutzt werden, um diese unstrukturierten Daten zu strukturieren (z.B. eine KI von Google, welche durchsuchbare Bildunterschriften für Fotos generiert). In der heutigen Zeit trifft man oft auf eine Mischung aus beidem, was grundsätzlich kein Problem ist, solange man nicht vergisst, die Daten korrekt zu erfassen: Strukturierte Daten sollten strukturiert gespeichert werden (z.B. in einer Datenbank) und unstrukturierte Daten sollten beim Abspeichern zumindest der Art oder Herkunft nach treffend bezeichnet werden, damit ein späterer Datenexperte nicht deren Bedeutung langwierig entschlüsseln muss, bevor er sie verwenden kann.
Typische Anwendungsgebiete von KI
Bis jetzt haben wir zum Verständnis der Thematik mit sehr abstrakten Beispielen gearbeitet, welche kaum wirtschaftliche Ziele abdecken (es sei denn, Sie planen Hunde auf Bildern zu erkennen als einen Kernelement Ihres Unternehmens auszubauen). An dieser Stelle würden wir Ihnen gerne die ideale KI-Strategie für Ihr Unternehmen und Ihren Anwendungsfall präsentieren. Da die Anwendungsfälle aber genauso unterschiedlich sind, wie ihre gesuchten Lösungen, ist dies leider unmöglich. Deshalb sind wir der Meinung, dass das endlose Nennen von KI-Beispielen ohne Kontext nur bedingt zu Ihrer Lösungsfindung beiträgt. Da es natürlich nicht ganz ohne gute Beispiele geht, wollen wir Ihnen hier eine Auswahl genereller KI-Lösungskonzepte vorstellen, welche durch Anwendungsbeispiele angereichert werden, um Ihnen den Transfer von diesen Konzepten zu Ihrem Anwendungsfall zu erleichtern.
Grundsätzlich können Probleme, welche man mit Machine Learning lösen kann, in mehrere Bereiche untergliedert werden. Über einige der interessantesten Bereiche bieten wir Ihnen hier einen Überblick:
Supervised Learning: Das Trainieren von KI anhand von Daten, welche bereits mit Erfahrungswerten (den sogenannten Labels) „beschriftet“ sind (z.B. Bild A: Hund; Bild B: Katze; Bild C: … oder Immobilie 1: 2 Mio. €; Immobilie 2: 1,8 Mio. €; Immobilie 3: …). Dieses Verfahren bezeichnet man auch als „Supervised Learning“, zu welchem auch Neuronale Netze und somit auch Deep Learning gehören:
- Regression (Abschätzen, Vorhersagen)
- Unter Regression versteht man eine mathematische Methode, die möglichst akkurat das vorhandene Problem durch eine Funktion beschreibt, welche durch Beobachtungen abgeleitet wurde. Möchte man z.B. den Verkaufspreis (Output Daten) einer Immobilie ermitteln, hängt dieser von gewissen Faktoren ab (Input Daten), darunter fallen beispielsweise die Lage der Immobilie, Größe des Objekts, Anzahl der Zimmer, etc.. Fakt ist, dass all diese Angaben in einer gewissen Art zusammenhängen und sich gegenseitig beeinflussen. Ein Regressionsmodell versucht nun basierend auf den Input Faktoren und den Mengen an tatsächlichen Objekten mit den bekannten Faktoren eine Funktion zu ermitteln, die möglichst genau die Ziel-Preise (Output) von den jeweiligen Immobilien ausgibt.
- Aber auch die Vorhersage von Trends ist mit Regression möglich und wird beispielsweise laufend an der Börse praktiziert. Hier werden die vermuteten Kursverläufe abhängig von den bisherigen Verläufen und weiteren Inputs (z.B. Nachrichten oder KPIs) vorhergesagt. Selbstverständlich ist auch hier wieder die trainierte Funktion effektiv ein statistisches Modell, das auf vergangenen Beobachtungen basiert und welches die Damen und Herren an der Börse nicht vor unerwarteten Ereignissen schützt (wie nicht zuletzt im Frühjahr 2020 gesehen).
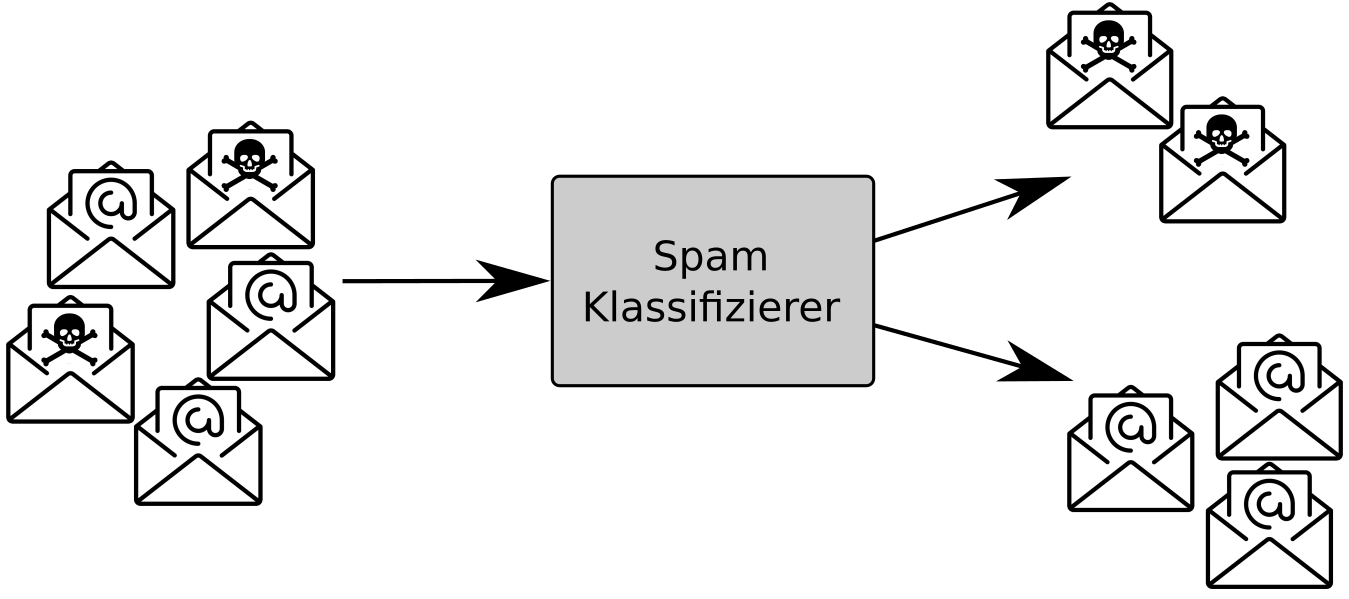
- Klassifizierung (Sortieren, Identifizieren eines Status)
- Wie bereits erwähnt handelt es sich beim Maschinellen Lernen um eine Mischung aus Informatik und Statistik. Hierbei spielt vorallem die Wahrscheinlichkeit bei der Klassifizierung eine entscheidene Rolle, nämlich zu wie viel Prozent einem gerade zu analysierenden Objekt ein bereits bekanntes/gelerntes Objekt zugeordnet werden kann. Um es etwas anschaulicher zu machen nehmen wir folgendes Beispiel eines automatischen E-Mail-Filters an. Dieser soll erkennen ob es sich bei einer eingehenden Mail um eine Spam – oder eine sichere Nachricht handelt. Dabei leitet ein ML-Klassifizierer, abhängig von Faktoren wie beispielsweise den Absender und den Inhalt der E-Mail der eingehenden Nachricht ab, wie hoch die Wahrscheinlichkeit ist, zu welcher Klasse die jeweilige Mail gehört. Ein Problem, welches sich hierbei ergeben kann, sind die sogenannten false positive, also jene E-Mails, die zwar kein Spam sind, aber trotzdem als solche klassifiziert werden. Ebenso können auch vermeintlich sichere E-Mails in Wahrheit Spam-Nachrichten sein, welche als false negative bezeichnet werden. Deswegen ist das Ziel eines Klassifizieres, diese beiden Zahlen möglichst gering zu halten ohne dabei die allgemeine Performanz einzuschränken indem der/die Informatiker/in im vornherein den jeweiligen Algorithmus des Klassifizierers möglichst gut kalibriert und anschließend genau testet.
- Das größte Anwendungsgebiet von Klassifizierung ist jedoch mit Abstand die Bilderkennung, also die Erkennung und Klassifizierung von Objekten auf Bildern. Hierbei geht der Algorithmus ähnlich vor, wie ein menschliches Individuum, indem er sämtliche Objekte die in seinem Blickfeld sind einem bereits gelerntem bzw. bekanntem Objekt zuordnet. Um diese Objekte voneinander abzugrenzen, werden unter anderem die Kanten der jeweiligen Objekte bestimmt, um so die Tiefe und die Umrisse dieser im Blickfeld zu bestimmen. Neben der Kantenerkennung gehören andere Merkmale wie Farbe und Form der Objekte zu entscheidungswichtigen Kriterien. Um es etwas anschaulicher zu gestalten nehmen wir folgendes Beispiel an: Ein Unternehmen fertigt täglich mehrere tausend unterschiedliche Schrauben, in variierender Länge und Art des Schraubenkopfs an. Um die Produktionsqualität festzustellen, wird jede Schraube per Hand von einem Menschen überprüft. Um diesen Verifikationsschritt durch einen Klassifizierer zu tätigen, benötigt dieser beispielsweise Videomaterial oder Infrarotaufnahmen der gefertigten Schrauben als Input, um eine Bewertung basierend auf den eingegebenen Einzelbildern und ggf. deren Abhängigkeiten zu treffen. Das hört sich zunächst sehr langsam an, jedoch kann ein richtig eingestellter Klassifizierer ein solches Live-Video, abhängig von der Geschwindigkeit des Fließbands, in Echtzeit analysiere. Das steigert zum einen den Wirkungsgrad der Produktion, minimiert die Personalkosten und ebenso die Fehlerquote.
Unsupervised Learning: Im Gegensatz zum Supervised Learing geht das Unsupervised Learning nicht davon aus, dass die Daten bereits ein Label haben, sondern beschäftigt sich unter Anderem damit das Label für die Daten selbst zu finden. Das für diesen Teilbereich interessanteste Verfahren ist neben der Dimensionalitätsreduktion (z.B. für eine bessere Darstellung oder Verarbeitung sehr komplexer Daten) ist das Gruppieren (Clustering) der Daten:
Beim Clustering werden die Daten ohne Label eingespeist und z.B. durch k-Nearest-Neighbor oder ähnliche Verfahren gruppiert. Das kann man sich wie folgt vorstellen: Daten, welche sich sehr ähnlich sehen, kommen in eine Gruppe, da sie, wenn man sie in ein Koordinatensystem zeichnen würde, sehr nahe beisammen liegen würden. Weiter entfernte Daten haben (vermutlich) ihr eigenes Cluster und unterscheiden sich stärker, je weiter sie entfernt liegen. Durch ein solches Clustering ist es beispielsweise möglich, Segmente in Kundendaten automatisch zu erkennen oder Nutzern Einkaufsvorschläge mit einem sogenannten Recommender System im Stil von „Kunden, die sich für dieses Produkt interessierten, interessierten sich auch für…“ zu unterbreiten. Aber auch das automatische gruppieren von Inhalten, wie Nachrichten oder anderen unstrukturierten Datensätzen gehört zu den Anwendungsgebieten des Clustering.
Reinforcement Learning: Die letzte Domäne des Machine Learning, auf welche wir hier eingehen wollen ist „Reinforcement Learning“. Bereits der eingangs erwähnte Herr Minsky hat sich Mitte des 20. Jahrunderts mit diesem Begriff auseinandergesetzt, da das Reinforcement Learning am meisten unserem „natürlichen“ Verständnis von Lernen entspricht. Reinforcement Learning findet immer dann Anwendung, wenn ein System nur begrenzt viele Aktionen durchführen kann und es schwierig ist, einer einzelnen Aktion eine „finale Bewertung“ (gut – schlecht oder passend – nicht passend) zuzuweisen. Stattdessen erhält das zu trainierende System eine Gesamtbewertung aller gewählten Aktionen (dem sogenannten Score). Somit ist es dem System möglich, verschiedene Kombinationen von Aktionen zu kombinieren und am Schluss eine Bewertung zu erhalten, wie gut diese Aktionen zusammengepasst haben.
Ein treffendes Beispiel ist das Navigieren von Robotern durch sich ändernde Umgebungen, wie in chaotisch organisierte Lagerhallen, in welchen der Ort eines angeforderten Produkts manchmal leider unbekannt ist (z.B. durch eine verpasste Buchung). Ob ein Roboter, der nun auf die Suche geschickt wird, nun links oder rechts hätte abbiegen sollen, um ein bestimmtes Produkt zu finden, kann nicht genau quantifiziert werden, solange unbekannt ist, wo sich das Ziel befindet. Jedoch ist es einfach, die Gesamtleistung des Roboters zu messen, indem der Roboter, der schneller am Ziel war einen höheren Score erhält, als der Roboter, der länger gebraucht hat, um das selbe gesuchte Produkt zu finden. So trainieren wir eine KI, die lernt, eine Suchstrategie anzuwenden, die den Roboter am zuverlässigsten in kurzer Zeit zu seinem Ziel führt und dabei die Struktur des chaotischen Lagers beachtet.
Quelle: Pixabay
Anwendungsfelder in der Industrie
Nun, da wir Ihnen eine gute Idee von den unterschiedlichen Problemen gegeben haben, welche von Künstlicher Intelligenz und Machine Learning gelöst werden können, möchten wir Ihnen als „Inspirationsquelle“ weitere, sehr spezialisierte Anwendungsfelder für KI aus der industriellen Praxis vorstellen. Die Liste der hier genannten Anwendungen ist, wie Sie mittlerweile sicher ahnen, nicht erschöpfend und dient allein der Anregung für Sie, in Ihrer Firma den passenden Anwendungsfall für KI zu bestimmen. Unseren Beitrag runden wir daher entsprechend mit einem Praxisbeispiel eines unserer Kunden und Forschungspartners ab.
Anwendungsfelder
Neben den klassischen und bereits erwähnten Beispielen von Klassifizierung (zuordnen von Input zu vorher festgelegten Klassen) und Regression (zuweisen eines kontinuierlichen Wertes zu einem gegebenen Input) gibt es einige weitere (Unter-)Bereiche, welche sich als besonders nützlich für die Industrie 4.0 herausgestellt haben:
- Image Recognition
Image Recognition bezeichnet den Prozess, bei dem ein Computer den Inhalt eines Bilds erkennen kann. Das kann von einfacher Erkennung der dominanten Farbe, bis hin zur Erkennung von äußerst komplexen Vorgängen wie z.B. der Interaktionen zwischen zwei Personen reichen. - Object Detection
Ein weiterer Bereich, welcher mit Bildern zu tun hat, ist die Object Detection. Hier wird nicht nur erkannt, was auf dem Bild zu sehen ist, sondern auch wo. Das erlaubt Systemen beispielsweise das Erkennen und Lokalisieren von Mängeln in Produkten auf einem Fließband. - Optical Character Recognition
Noch detaillierter wird es bei OCR: Hier werden einzelne Buchstaben erkannt und meist von analog zu digital transformiert. Ob die Buchstaben davor digital waren oder handgeschrieben sind ist dabei unerheblich. - Natural Language Processing
Aufbauend auf OCR ist es z.B. möglich durch Anwendung von NLP den Inhalt des Geschriebenen zu klassifizieren und somit zu erkennen, ob es sich bei dem erkannten Text um einen Namen, einen Befehl für Alexa oder einen KI-Artikel handelt. Über die reine Erkennung des Inhalts hinaus beschäftigt sich NLP vor allem mit der Erkennung der Semantik des erfassten Texts (egal ob via OCR, Mikrofon oder anderem Input eingegeben), um davon Aktionen abzuleiten. Das beste Beispiel hierfür sind natürlich die Smart-Assistants, die in den letzten Jahren großen Einzug in Smartphones und -Homes gefunden haben. - Time Series Prediction
Die Vorhersage von Zeitreihen ist ein weiteres Gebiet der KI. Hierbei versucht das System vorherzusagen, wie sich ein Trend in Zukunft fortsetzen wird. Dabei werden neben den kürzlich beobachteten Daten auch sogenannte „Seasons“ (also regelmäßig, jedoch nur intervallweise auftretende Veränderungen) oder Langzeittrends berücksichtigt. Somit ist es beispielsweise möglich, Verkaufszahlen besser vorherzusagen, um somit seine Vertriebsmitarbeiter zur richtigen Zeit am richtigen Ort einzusetzen. - Anomaly Detection
Wie der Name bereits treffend beschreibt, geht es in der Anomaly Detection darum, Anomalien so gut wie möglich von dem „regulären Fluss der Dinge“ zu unterscheiden. Beispielsweise könnte eine KI Anomalien im firmeninternen Netzwerk erkennen und somit bei einem Cyber-Angriff Alarm schlagen. Aber auch Erkennung von Abweichungen in der Produktion oder im Mitarbeiterverhalten sind denkbare Anwendungsszenarien. - Predictive Maintenance
Das letzte Feld, welches wir hier ansprechen wollen ist Predictive Maintenance. Vor allem im Feld des Internet of Things (IoT) hat Predictive Maintenance großen Einzug gehalten. Dabei geht es darum, erweiternd zur Time Series Prediction und der Anomaly Detection vorherzusagen, wann eine Maschine demnächst Wartung braucht. Auch hier können Kosten gespart werden, indem Service-Mitarbeiter zur richtigen Zeit bei dem richtigen Kunden eingesetzt werden.
KI am Beispiel: Das Forschungsprojekt INVIA
Ziel des Forschungsvorhabens INVIA war die Erforschung, Konzeption und prototypische Umsetzung eines neuartigen, mobilen, cloudgestützten Assistenzsystems für das Training, die Diagnose und den Service komplexer Landmaschinen. Dabei werden folgende Use Cases betrachtet:
- Die interaktive Unterstützung des Fahrers durch bild- und videogestützte Diagnose durch Spezialisten in den Niederlassungen oder in der Werkszentrale
- Die interaktive Unterstützung des Servicetechnikers durch Experten in der Werkszentrale auf Basis von Augmented Reality (AR) und vernetzten Diagnosetools
- Das onlinegestützte Training des Fahrers durch ausgebildete Trainer während der Erntekampagne („training on the job“)
Der KI-Part in diesem Projekt ist jedoch im Detail versteckt: Da auf dem Feld die mobile Internetverbindung meistens nicht perfekt ist und mehrere HD-Videostreams von der Landmaschine (Innenkamera und mehrere Außenkameras), der Maschinenkonsole mit allen Fehlermeldungen und dem Smartphone des Fahrers zu viel Bandbreite benötigen würden, muss intelligent entschieden werden, welcher Stream in HD übertragen werden soll und welcher Stream auch in Low-Quality genügt.
Um diesen Engpass zu bedienen haben wir ein KI-System entwickelt, das mit Hilfe von Object Detection feststellt, in welchem Kamerabild sich gerade eine Person bzw. relevante Maschinenbauteile befinden. Sobald unsere KI den Inhalt des Videos klassifiziert hatte, konnten wir diesen Video-Streams automatisch eine höhere Bandbreite zuweisen, da in diesen offensichtlich gerade „relevante“ Daten präsentiert werden.
Hierfür analysieren wir einzelne Frames des Videos (also Standbilder), die stichprobenartig entnommen werden, sodass das trainierte ML-Modell auch auf schwacher Hardware performant läuft. Die größte Schwierigkeit in diesem Projekt war das Beschaffen des Datensets, da die benötigten Bilder im Vorhinein nicht vorhanden waren und künstlich erzeugt werden mussten.
Weitere allgemeine Informationen zu unserem Forschungsprojekt zusammen mit dem Fraunhofer Institut finden Sie hier.
Experten für Ihr Digitalisierungsprojekt
Wenn Sie ein KI-Projekt planen oder wie wir daran glauben, dass KI unseren Firmenalltag innerhalb der nächsten Jahre ähnlich prägen wird, wie die Einführung des Internets oder der elektronischen Datenverarbeitung, dann lassen Sie uns doch gerne unverbindlich über Ihre persönliche KI-Strategie sprechen!
In the past a lot of S&P 500 CEOs wished they had started thinking sooner than they did about their Internet strategy. I think five years from now there will be a number of S&P 500 CEOs that will wish they’d started thinking earlier about their AI strategy.
Prof. Andrew Ng, VP & Chief Scientist bei Baidu 2016

Simon Lang ist seit 2015 bei Weptun als Projektmanager und Entwickler angestellt. Dabei betreut er Kunden von der Ideen-Phase bis weit nach Projektabschluss technisch und organisatorisch. Neben der App-Entwicklung gehört besonders der Bereich KI zu seinen technischen Kernkompetenzen.